Sentinel在IoT业务中台的应用
作者:杨林 | 基础研发平台-IoT中心-IoT业务部
编辑:西顿小编 | 人力资源中心
可靠性是IoT业务中台对外提供的最基础承诺,但当微服务体系日益庞大后,接口间相互依赖和调用也趋于复杂,在这样的环境下,如果某个接口不可用或者某个时刻请求量过载,导致出现整个系统不可用的风险也大大增加,为了应对这样的风险,有必要在服务接口出现“状况”时,提供熔断与限流的保护。
我们通过选择开源的Sentinel中间件来支持对IoT业务中台dubbo微服务系统的熔断与限流保护,并对Sentinel做了两个有用的改造:
1) 对接Apollo配置中心进行规制下发
2)在熔断后提供了一个基于配置的自动降级方案
技术选型
我们对Netflix的Hystrix以及阿里的Sentinel做了一些比较,Hystrix可以说是直插心肝,直接解决最迫切的问题(熔断降级,资源隔离),Sentinel也解决了这些问题,而且在解决核心问题的基础上做了一些延生,比如系统自适应保护、黑白名单控制等。二者在功能上都可以满足我们当前的需求,最终我们选择了阿里的Sentinel,因为它的功能比较丰富,并且提供了与dubbo的无缝对接,可以在不侵入现有dubbo服务的基本上透明地接入Sentinel。
Sentinel团队在github上做了一个Sentinel与Hystrix的详细对比,感兴趣的同学可以访问https://github.com/alibaba/Sentinel/wiki/Guideline:-%E4%BB%8E-Hystrix-%E8%BF%81%E7%A7%BB%E5%88%B0-Sentinel查看,下图是Sentinel的主要特性:
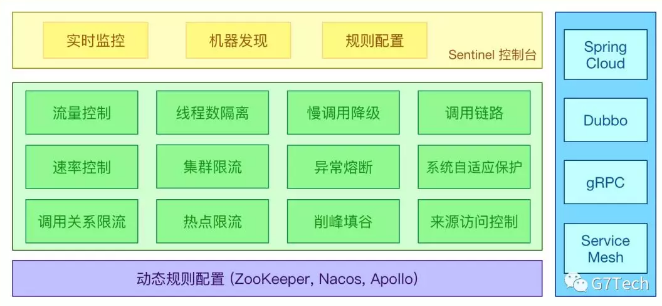
基本原理

Sentinel会通过滑动窗口实时地记录一些统计信息,比如当前的并发数,当前的QPS,当前的异常数等。当每次服务被调用或者调用第三方服务的时候,Sentinel都会把当前的统计信息与我们配置的阀值进行对比,如果超过了我们的配置的阀值就会触发我们配置的行为。
举例说明,应用可以配置这样一个规则:Service A这个资源允许最多20个线程的并发使用,假设接下来调用Service A会导致其最大并发数超过20,那么这时候的行为是直接拒绝执行(CONTROL_BEHAVIOR_DEFAULT默认行为)。应用这个规则时,Sentinel大概的执行流程如下:

配置下发
Sentinel的规则下发比例原始,每次只能针对集群中的某台机器进行设置,假如集群里面有20台机器就需要分别设置20次:

如果集群中机器的配置或处理能力存在差异,那么这种方法是可取的,目前我们的系统中机器的配置和处理能力几乎是对等的,需要更方便的一次性的规则下发方式。目前IoT统一部署的Apollo配置中心就可以很好地实现这一目的,可以省去从零自建的麻烦,调整后的规则发下变成了这样:

通过Apollo对外的Http接口,我们实现了上图的逻辑,这样的配置规则就方便了许多,而且也可以保持各个机器节点规则的一致性。Apollo也提供了本地缓存的功能,即使Apollo发生故障,各个机器节点也能应用本地缓存的规则。
统计QPS
对线上已有服务配置限流的时候,我们需要谨慎一些。比如配置QPS限流的时候,我们不能随意设置一个最大的QPS,如果配置的最大QPS比如线上实际出现的最大QPS小的时候,线上的服务就会出现问题(报错)。
针对这种情况我们改造了Sentinel,以集群的视角统计集群每小时的统计信息,比如每小时的最大QPS,异常数量等,为线上已有的服务配置限流规则提供一些参考信息。
线程(池)隔离
任何资源,总是有限的,硬盘内存不可能无限大,CPU不可能处理任意量级的运算,数据库连接不可能无限多。虽然资源是有限的,但是需要处理的任务是无限的,在任务是无限的,资源是有限的情况下,这些有限的资源只能通过共享的方式来完成这些无限的任务。当某个任务一直占用所有共享的资源的时候,其它任务当然就无法正常完成。
在实际的应用中,我们的每个服务都是需要共享线程(池)来处理任务,因此我们需要保证在某个服务出现问题的时候不会霸占所有的共享线程,影响其它同样依赖这些共享线程的服务。Sentinel提供了基于信号量(计数)的线程隔离方案,可以为每个服务分别设置允许的最大的并发数。我们在为一个服务设置具体的并发线程数的时候,需要有一些基本的认识:
· 设置的线程数即要满足线上实际的服务调用(可用QPS做为依据),也要能兼容一定程度上的抖动
· 当服务出现问题的时候,即使分配给这个服务再多的线程,也可能无法处理所有服务请求
· 目标是:某个服务出现问题的时候(比如: 处理时间变得特别长),其占用的线程数不会无限扩大,造成其它服务饿死
· 目标<<不>>是:设置足够大的线程数,即使服务使出现了故障也要保证处理所有的服务请求
当这些认识达到一致的时候,我们也许可以通过这样的一种方式来计算出一个服务具体需要多少的线程(供参考):

降级方案
IoT内部的系统有很多,这些系统分别都有不同的功能、职责,各自以集群的方式部署。它们之间往往通过服务接口的方式协同完成某项具体的内部或外部业务,系统之间的调用形成了庞大而又复杂的调用关系层次,就像这样:
如果某个基础设施服务出现了故障,那么所有直接和间接依赖这个服务的上层服务都会出现故障,造成可怕的级联失败,导致所有相关的业务不可用:

当依赖的下层服务出现故障时,如果可以找到合适的降级方案,就可以防止故障的进一步扩散,保障上层服务的可用性。针对适合应用缓存降级的业务,我们统一封装了一些缓存降级逻辑,方便大家使用:

基于内存的缓存。内存缓存成本很低,不需要额外的服务器资源。缺点是单机命中率低,不过配合失败重试,可以达到一个相对较高的整体命中率。

目前我们Dubbo服务接口的返回值的类型普遍都有setter,业务代码经常比较随意地使用这些setter来实现业务功能,一旦降级发生,从缓存里面取的值就是修改后的值,而不是Dubbo服务接口返回的原始值,出现数据污染,这样很大机会上会造成业务逻辑的错误。因此提供了2个拷贝的配置项,来避免数据污染的出现:
1. 如果返回类型只是简单的带有settter的DTO,只需要将shallowCopy设置为true;
2. 如果返回类型是嵌套的带有settter的DTO,那么需要将deepCopy设置为true;
3. 如果返回类型是不可变的(或事实不可变的),那么就没有数据污染的问题,可以同时将shallowCopy和deepCopy设置为false;
· 基于Redis的缓存。Redis缓存可以提高命中率,缺点是需要单独的Redis资源,与正常的业务Redis隔离,避免相互影响。
目前各个系统经常使用两个第三方库来接入Redis: JedisPool和RedisTemplate, 我们也对应地引入了2个配置类: JedisPoolCacheFactory, RedisTemplateCacheFactory,这2个类的配置都比较简单,只需要设置对应的JedisPool或RedisTemplate即可。
· Async缓存。Async缓存与Redis缓存配合使用,消除写Redis带来的额外延迟。

异常更新缓存使用批量更新的方式来异步写Redis缓存,需要更新的值临时保存在内存中,每flusMs写一次远端Redis,需要设置了一个合适的flushQueueSize,避免Redis出现故障时内存被耗尽。
Fallover缓存。每当依赖一个新的组件的时候,都需要想到这个组件也可能出现失败,Fallover缓存可以组装成多级缓存,提高可靠性。
所有的这些缓存都提供了灵活的配置选项,可以适应不同的应用场景。将降级方案与dubbo透明的集成起来可以减少对业务代码的侵入,我们扩展了dubbo的cluster,在下层服务集群整体表现出失败的时候(重试完任然失败),将从缓存中获取数据并返回。
总结
分布式系统比单机系统存在更多的不确定因素,比如说网络可能出现不稳定,节点假死/故障等,依赖调用的服务忽然面临超负荷的压力而无法成功调用等,在面对这些不确定性,所有的这些措施更多的是应对异常情况。故障是不可避免的,在分布式系统中的,就算是发生故障,也应该让故障变得可控,让受影响的用户尽量少,让故障的时间不断变短。
作者简介
杨林,JAVA开发工程师
目前服务于IoT业务部小组
喜欢对各种框架刨根问底
周末没事常去星巴克撸代码
本文来源微信公众号;G7Tech,建议关注,还有更多精彩内容
下一篇:物联网智能井盖解决方案
